
Martin Schmid y otros expertos del equipo de inteligencia artificial de DeepMind han desarrollado un IA polivalente que es capaz de aprender y ganar en juegos totalmente diferentes. Esto es toda una demostración sobre lo flexibles que pueden llegar a ser las IAs para el desempeño de diversas tareas, en vez de estar limitadas a un solo campo. El desarrollo lo han llevado a cabo con juegos que van desde los más estudiados, conocidos y rígidos, como el ajedrez, a otros en los que el azar juega un papel importante, como el póker o el Scotland Yard, un juego de tablero de detectives para varios jugadores donde unas cartas mezcladas son un factor importante.
Información perfecta, información imperfecta
 En la clásica obra de John von Neumann y Oskar Morgenstern, ‘Theory of Games and Economic Behavior‘ (1944) se establecieron muchas de las bases de la teoría de juegos moderna. Más allá de establecer un paralelismo entre algunos aspectos del mundo real y su versión simplificada como juegos matemáticos, von Neumann y Morgenstern establecieron los distintos tipos de juegos: cooperativos, simultáneos, secuenciales, de suma cero…
En la clásica obra de John von Neumann y Oskar Morgenstern, ‘Theory of Games and Economic Behavior‘ (1944) se establecieron muchas de las bases de la teoría de juegos moderna. Más allá de establecer un paralelismo entre algunos aspectos del mundo real y su versión simplificada como juegos matemáticos, von Neumann y Morgenstern establecieron los distintos tipos de juegos: cooperativos, simultáneos, secuenciales, de suma cero…
Una de las tipologías más importantes tiene que ver con la diferencia entre los juegos de información perfecta y los de información imperfecta. En los primeros, los jugadores conocen en todo momento el estado completo del juego: qué movimientos se han efectuado hasta el momento, cuál es el turno, y por tanto dónde están todas las piezas, qué posibilidades tiene cada jugador, etcétera. Los ejemplos más habituales de juegos de información perfecta son el ajedrez y el go.
En los juegos de información imperfecta, en cambio, los jugadores no siempre cuentan con esa información, porque está oculta o depende del azar. Una partida de póker en la que los jugadores ocultan sus naipes no permite conocer todas las posibilidades futuras. Los juegos con dados o factores aleatorios (por ejemplo, mezclar las cartas de «Suerte» en el Monopoly) requieren tomar decisiones según el cálculo de probabilidades.
Un «estudiante de juegos» como inteligencia artificial
Son de sobra conocidos los avances que la IA ha hecho en juegos como el go (con AlphaGo) y el ajedrez (Stockfish y AlphaGo Zero), con demostraciones escalofriantes como aprender ajedrez desde cero en menos de 4 horas y ganar a los grandes maestros. Pero es que además de eso la gente de DeepMind desarrolló DeepStack, capaz de ganar al póker (al menos «estadísticamente»; ganó a todos menos a uno de los 33 jugadores profesionales tras 3.000 partidas con cada uno de ellos). Un equipo de IAs completo y variado.
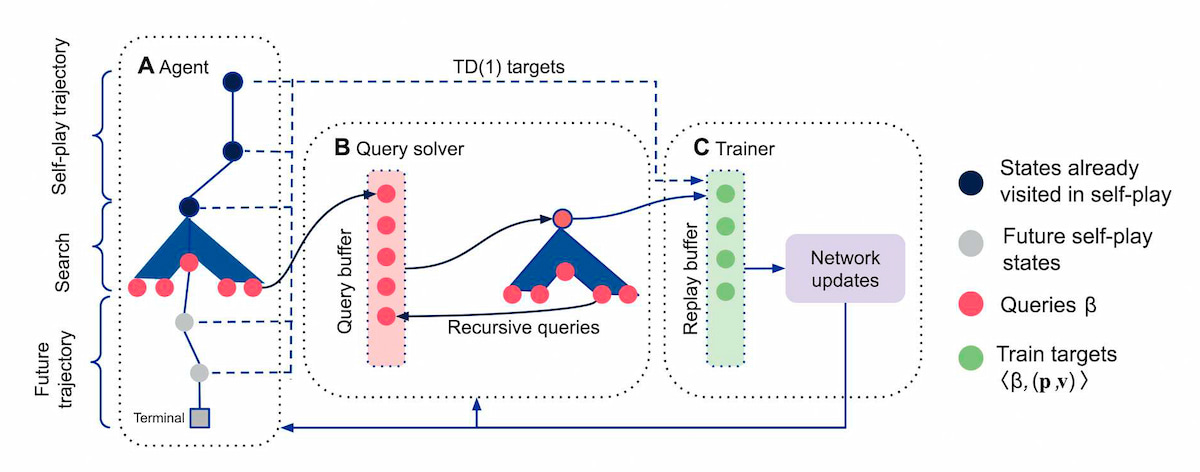
El nuevo desarrollo de DeepMind se llama Student of Games (SoG) y es una inteligencia artificial que combina tanto el aprendizaje para juegos de información perfecta como imperfecta. La clave es que su versatilidad le permite hacer ambas cosas y, en cierto modo, parecerse más a lo que sería el «rendimiento superhumano» o la AGI (Inteligencia Artificial General), aunque llamarla así en el punto en que está sería, sin duda, un tanto exagerado.
Una inteligencia artificial con un plan para aprender a jugar
El algoritmo de SoG no es fácil de entender sin grandes conocimientos matemáticos y de teoría de juegos, pero se basa en una idea llamada GT-CFR (abreviatura de «razonamiento de teoría de juegos y minimización del arrepentimiento ante hechos contrastables»), que recuerda vagamente al razonamiento humano y que básicamente se lleva a cabo en cinco pasos:
- Imaginar las posibilidades. Primero se visualiza un «árbol» de posibles movimientos del juego desde la situación actual, en el que cada rama del árbol representa una decisión o movimiento posibles.
- Decisiones inteligentes. Se decide qué parte del árbol explorar más en profundidad, según los movimientos más prometedores. Es una especie de predicción de por dónde se puede llegar a mejores resultados.
- Aprender de los errores (arrepentimiento). Si se elige un camino incorrecto, se toma nota para evitar ese tipo de decisiones en el futuro.
- Hacer crecer el árbol de manera inteligente. El algoritmo se enfoca en las partes del juego que parecen más importantes y hace crecer el árbol en esas zonas respecto a otras.
- Mejora continua. A medida que el juego avanza se van mejorando las estrategias, aprendiendo de movimientos pasados y ajustando las predicciones. Con el tiempo se vuelve cada vez mejor.
Con esta idea el SoG no es tanto una IA para jugar como una IA para aprender a jugar, y resulta válida tanto para los juegos con conocimiento perfecto como imperfecto. Las pruebas fueron muy prometedoras en los juegos tradicionales, desde el ajedrez al póker Texas Hold’em, e incluso el juego de tablero Scotland Yard donde varios jugadores se mueven por un mapa de Londres y hay naipes de suerte mezclados que determinan las diversas opciones.
El resultado no es todavía tan bueno como las IAs especializadas (para go o ajedrez) pero es capaz de vencer a los jugadores humanos, algo que resulta bastante impresionante en cualquier caso, y teniendo en cuenta que las IAs especializadas no pueden salir de su campo.
Algoritmos como SoG pueden ser más prácticos para el mundo real, en el que un robot marciano puede encontrarse con obstáculos en su camino, un vehículo autónomo con imprevistos de todo tipo o un robot logístico algo impredecible y complejo que nunca haya visto. Imaginar, tomar decisiones, rectificar, aprender… Todo terminología muy humana.


