En el campo del reconocimiento del habla mediante inteligencia artificial –algo que usamos en los smartphones al dar instrucciones a los sistemas de navegación al conducir o con los asistentes digitales como el de Google, Siri o Alexa– se utilizan diversas técnicas de entrenamiento para conseguir que hagan su «magia». Una de las más habituales requiere contar con inmensas fuentes de datos: horas y horas de conversaciones, textos leídos en voz alta o grabaciones de radio y televisión, de las cuales se cuenta con una transcripción en texto, de modo que se puedan hacer coincidir las palabras, frases y fonemas con lo que se está oyendo.
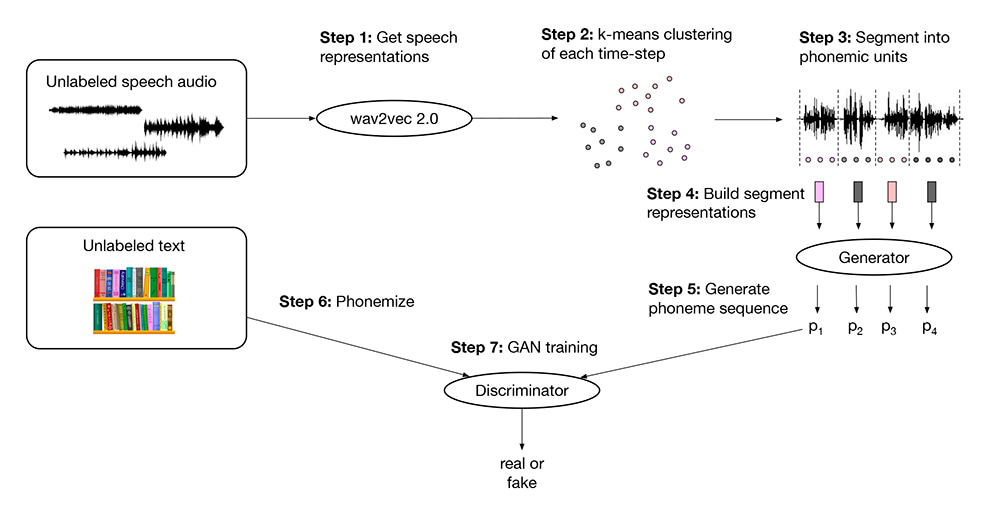
Ahora en los laboratorios de Facebook han revelado que llevan años trabajando en una nueva técnica que han llamado «Reconocimiento de habla sin supervisión (Wav2vec-U)», que es capaz de hacer lo mismo, pero sin tantos requerimientos. Entre otras cosas, no requiere convertir el habla en texto transcrito, sino que puede pasarse directamente de texto hablado a fonemas.
Esto ofrece las siguientes ventajas:
- Se puede reconocer el habla de muchos más idiomas, incluyendo aquellos que al ser minoritarios no cuentan con grandes corpus de material grabado con el que entrenar a las máquinas.
- Se pueden reconocer acentos, dialectos, estilos y otros matices, algo que las personas hacemos fácilmente, pero a las máquinas les cuesta mucho si no cuentan con un entrenamiento específico.
- Al no necesitar transcripciones ni tantas horas de entrenamiento, los algoritmos son más eficientes, de modo que todo el proceso es energéticamente más limpio: se consume menos energía y por extensión se generan menos emisiones contaminantes en los centros de datos y en la nube, que es donde se suele realizar ese procesamiento.
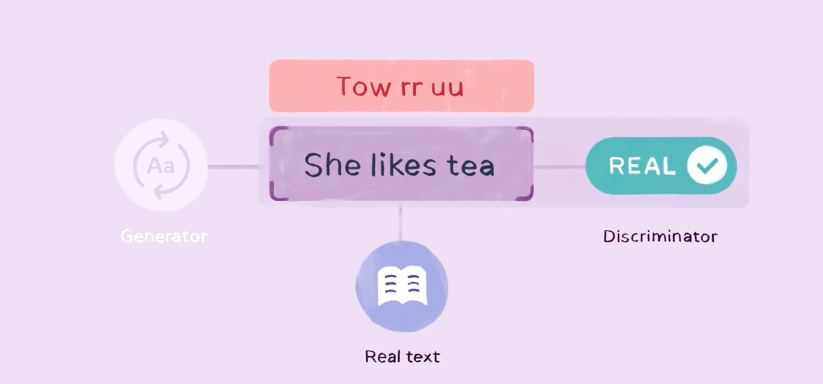
Normalmente estos modelos requieren unas 1.000 horas de audio para que un entrenamiento resulte eficiente. La forma en que funcionan consiste en escuchar el audio original y usar un método de verificación para irlo marcando como válido o inválido. Este algoritmo utiliza, en concreto, una red generativa antagónica y un discriminador, dos componentes que son parte del algoritmo y que actuando juntos van convirtiendo los diversos «intentos de reconocimiento» de algo ininteligible a algo con sentido y fonemas válidos.
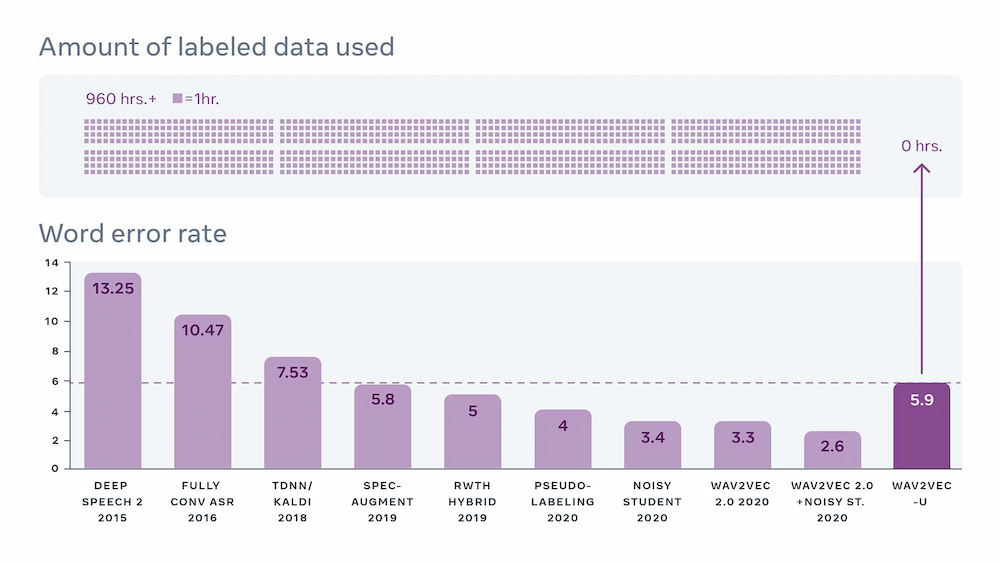
El resultado final es un algoritmo con un ratio de errores razonablemente bueno, comparable con el de los mejores sistemas de hace un par de años, pero que no necesita ni un minuto de audio transcrito para su entrenamiento, por lo que puede funcionar con todos los idiomas y acentos.
Facebook ya ha liberado el código de Wave2vec-U, de modo que otros equipos de investigación puedan examinarlo, probarlo y mejorarlo, un proceso habitual en este campo y en muchos otros de la tecnología. La idea última es que no sólo existan mejores sistemas para el reconocimiento del habla, sino que estos sistemas lleguen a más personas, a cualquier parte del mundo, hablen el idioma que hablen. Si además se consigue que sean más eficientes energéticamente y, por ende, generen menos emisiones contaminantes, mejor que mejor para el planeta.


