Aunque muchas veces se nos pasa por alto, aunque observamos las tres dimensiones del «mundo real» sin problemas, todas las imágenes de fotografías y películas están en 2D, incluyendo las que captamos con el fondo de nuestras retinas de nuestros ojos. Es el cerebro el que reconstruye el efecto de volúmenes y distancias para que los píxeles cobren sentido en un entorno espacial. Y aunque utilizar dos ojos en vez de sólo uno proporciona cierta ayuda estereoscópica –con algunos píxeles cambiando sutilmente de posición– en general también no tenemos problemas para interpretar una foto o una película con un ojo abierto y otro cerrado. Pero esto no es algo que sólo pueda hacer nuestro cerebro: también los ordenadores son ya hábiles con ello.
Unos investigadores de las Universidades de Berkeley, San Diego y Google Research llevan tiempo trabajando en esta técnica y recientemente la tecnológica NVIDIA ha dado a conocer algunas demostraciones sobre los avances que están realizando en cómo convertir imágenes 2D en 3D sin más ayuda que las propias imágenes. Es algo que puede ser muy útil en diversos entornos en los que se usen cámaras convencionales, incluyendo los de reconocimiento de imágenes, interpretación de entornos 3D como los que necesita un vehículo durante su conducción y similares. Lo mejor es que para esta tarea no se necesitan sensores especiales, LiDAR ni nada parecido: bastan las puras y simples imágenes planas que captan las cámaras de fotos / vídeo.
La técnica que se emplea se conoce como réndering inverso, a diferencia del renderizado convencional que es el que se utiliza en videojuegos para crear imágenes realistas y con texturas a partir de un modelo 3D de la escena. El punto de partida, en este caso, son unas cuantas docenas de imágenes, normalmente rodeando al sujeto de la escena o al punto de mayor interés, donde los algoritmos examinan cómo se comporta la luz incidente de cada píxel. La tonalidad de cada píxel y el ángulo de las cámaras permiten determinar el color original, pero además de eso el brillo de esos puntos y los que están cerca definen cómo está iluminada la escena, algo que un algoritmo de inteligencia artificial puede desentrañar.
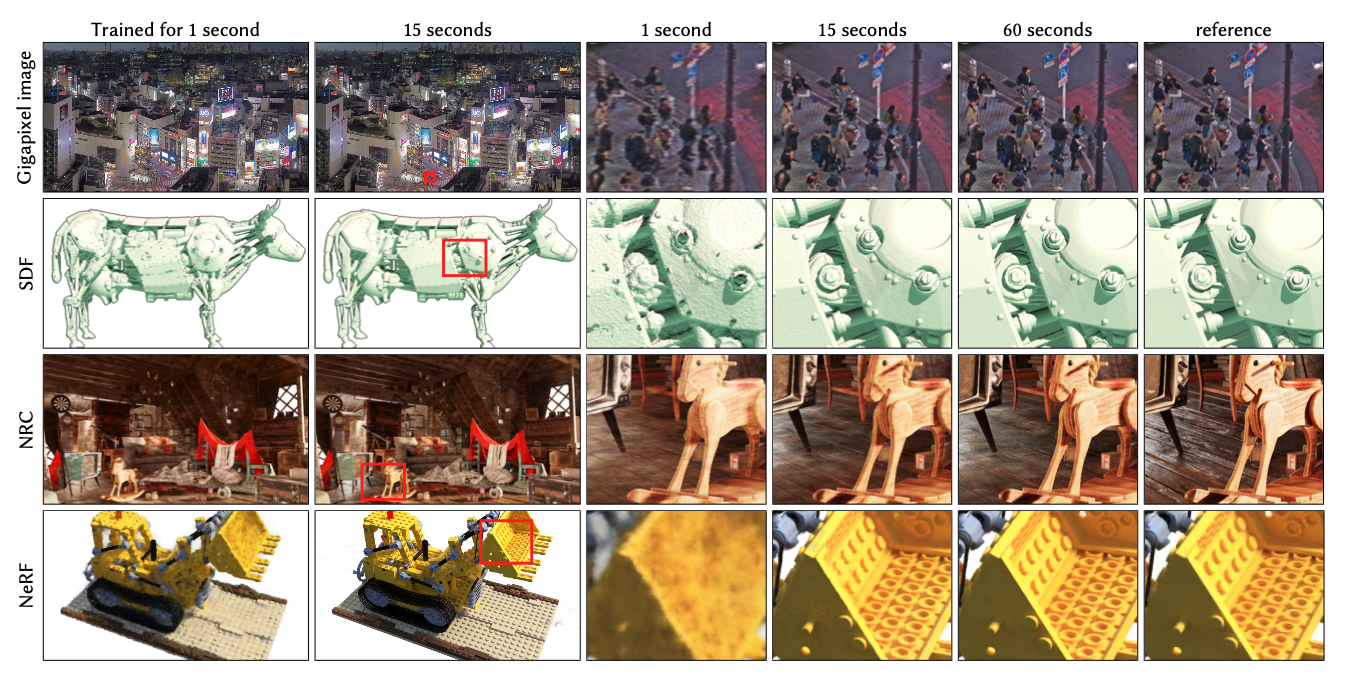
 Esa segunda parte del proceso se conoce como Campos de Radiación Neuronal (NeRFs) y, como suele suceder con estos algoritmos, se «entrenan» con varias imágenes –en este caso, algo más de una docena– en unos pocos segundos. El algoritmo proporciona una imagen tosca en los primeros milisegundos, pero mejora a medida que se le permite aprender un poco más, dando lugar imágenes mucho más nítidas y con detalle. En las pruebas, a partir de 15 segundos se producen ya imágenes casi indistinguibles del original de referencia. Algunas de las GPUs (Unidades de Procesamiento Gráfico) de NVIDIA tienen suficientemente potencia para hacerlo mediante una técnica que produce resultados muy rápidos y en alta resolución a partir del aprendizaje de esas redes neuronales.
Esa segunda parte del proceso se conoce como Campos de Radiación Neuronal (NeRFs) y, como suele suceder con estos algoritmos, se «entrenan» con varias imágenes –en este caso, algo más de una docena– en unos pocos segundos. El algoritmo proporciona una imagen tosca en los primeros milisegundos, pero mejora a medida que se le permite aprender un poco más, dando lugar imágenes mucho más nítidas y con detalle. En las pruebas, a partir de 15 segundos se producen ya imágenes casi indistinguibles del original de referencia. Algunas de las GPUs (Unidades de Procesamiento Gráfico) de NVIDIA tienen suficientemente potencia para hacerlo mediante una técnica que produce resultados muy rápidos y en alta resolución a partir del aprendizaje de esas redes neuronales.
 El resultado es que el algoritmo es capaz de generar, en unos pocos milisegundos, todas las imágenes necesarias para un suave recorrido en 3D, que permita ver los objetos tridimensionales como si hubieran sido generados o fotografiados a partir de un modelo tridimensional, cuando en realidad han sido más bien «adivinados» a partir de unas pocas fotos tomadas, desde distintos ángulos, unos segundos antes. Entre otras aplicaciones, los investigadores hablan de la recreación de mapas, objetos tridimensionales, detalles arquitectónicos y similares. Desde luego es una solución que parece producir unos resultados estupendos y que no requiere de hardware especializado ni de costosos equipos de visión estereoscópica, LiDAR ni otras complicaciones que pueden ser por tanto consideradas innecesarias.
El resultado es que el algoritmo es capaz de generar, en unos pocos milisegundos, todas las imágenes necesarias para un suave recorrido en 3D, que permita ver los objetos tridimensionales como si hubieran sido generados o fotografiados a partir de un modelo tridimensional, cuando en realidad han sido más bien «adivinados» a partir de unas pocas fotos tomadas, desde distintos ángulos, unos segundos antes. Entre otras aplicaciones, los investigadores hablan de la recreación de mapas, objetos tridimensionales, detalles arquitectónicos y similares. Desde luego es una solución que parece producir unos resultados estupendos y que no requiere de hardware especializado ni de costosos equipos de visión estereoscópica, LiDAR ni otras complicaciones que pueden ser por tanto consideradas innecesarias.


